文章目录
- 1. UDP
- 1.1 UDP 头部
- 1.2 UDP 校验和
- 1.3 UDP 传输过程
- 1.4 UDP-Lite
- 1.5 最大 UDP 数据报长度
- 1.6 UDP 输入队列
1. UDP

UDP:用户数据报协议(User Datagram Protocol)面向无连接的,也就是无需建立连接,传输不可靠。UDP仅仅是在IP服务的基础上增加了进程到进程之间的通信,使其不再是主机到主机的通信。
UDP是一个简单的==面向数据报==的传输层协议:进程的每个输出操作都正好产生一个UDP数据报,并组装成一份待发送的IP数据报。如果IP数据报的长度超过网络的MTU,就要对IP数据报进行分片。如果需要,源端到目的端之间的每个网络都要进行分片。
应用在对可靠性要求不高,传输速度和延迟要求较高时,用UDP代替TCP。UDP没有确认技术和滑动窗口机制。
为什么使用UDP
-
更快,没有繁冗的建立过程。
-
更少的报文类型,没有握手包,结束包,不需要数据确认包。
-
需求更少的本地资源,不需要追踪每对seq和对应的ack。
-
通常用在视频,语音通话等。
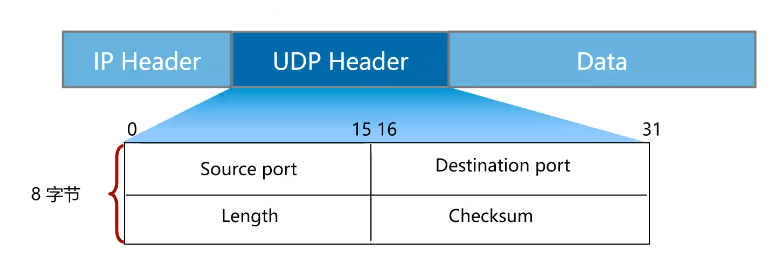
1.1 UDP 头部

TCP端口号和UDP端口号是相互独立的。(rsh和syslog=514)
尽管相互独立,如果TCP和UDP同时提供某种知名服务,两个协议通常选择相同的端口号,就是为了方便,而不是协议本身的要求。(DNS端口53)
说明:
-
UDP也分为头部和数据区域两部分。UDP适合于实时数据传输,语言和视频通话。无法保证数据传输的可靠性。
-
Source Port和Destination Port:包含16位源端口号和16位目标端口号。(端口范围0-65535)
-
Length:16位UDP长度,与TCP不同,这里指的是头部和数据的字节长度。UDP头部长度为8字节,所以最少是8。
-
Checksum:16位UDP校验和,与TCP相同功能,该字段可选。(操作系统可以选择不计算UDP的校验和)

-
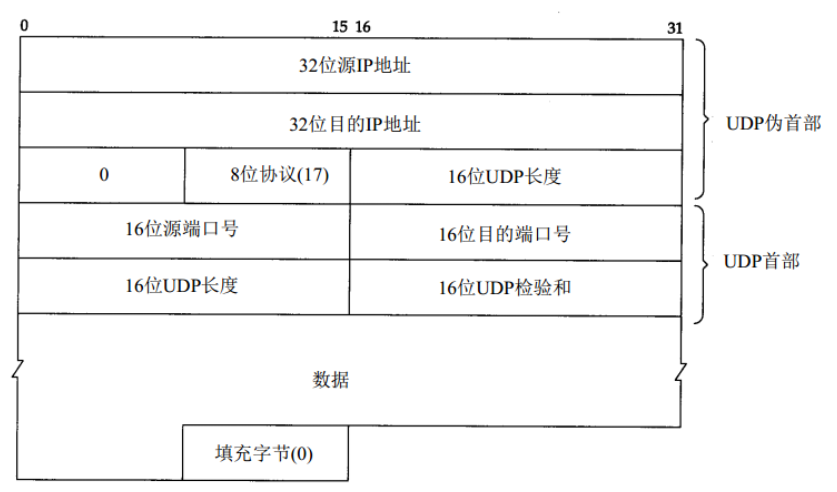
伪首部的目的是在传输层检验数据的完整性。
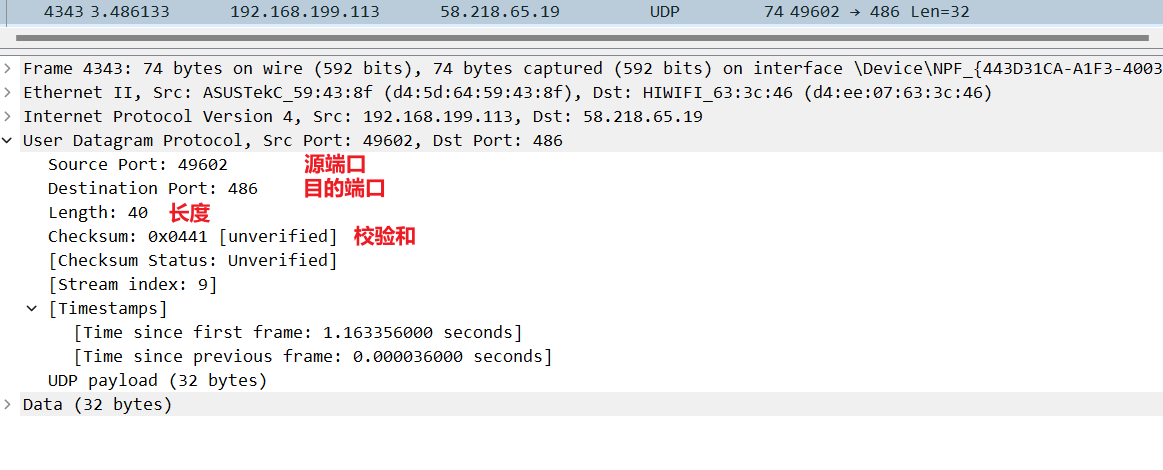
Wireshark抓包查看
1.2 UDP 校验和

-
UDP检验和覆盖UDP首部和UDP数据。UDP和TCP在首部中都有覆盖它们首部和数据的检验和。
- 当UDP数据包被发送出去时,发送方会计算UDP首部和数据部分的检验和,并将这个检验和值放置在UDP首部中的检验和字段中。
- 当接收方在接收到UDP数据包后,也会重新计算UDP首部和数据部分的检验和,并将结果与UDP首部中的检验和字段进行比较。如果两者一致,说明数据包在传输过程中没有发生错误,可以被接收方信任;如果不一致,则说明数据包可能已经损坏或者被篡改,接收方可能会丢弃这个数据包或者请求重新发送。
-
IP首部的校验和,只对IP的首部进行校验。
-
UDP的校验和字段是可选的(操作系统可以选择不计算UDP的校验和),而TCP的校验和字段是必须的。
-
UDP数据报和TCP段都 “包含” 一个12字节的伪首部,它只是为了计算检验和而设置的,并不是真正的首部。其目的是让UDP两次检查数据是否已经正确到达目的地。(例如:IP没有接受地址不是本主机的数据包,以及IP没有把应传给另一个高层的数据报传给UDP)
-
IP计算校验和和UDP计算检验和之间存在不同的地方。首先,UDP数据报的长度可以为奇数字节,但是校验和算法是把若干个16bit字相加。解决方法是必要时在最后增加填充字节0,这只是为了检验和的计算(也就是说,可能增加的填充字节不被传送)
如果接收端检测到检验和有差错,也就是发送出去的数据报和收到的数据报中的校验和值不一致,那么UDP数据报就被悄悄地丢弃,不产生任何差错报文(当IP层检测到IP首部检验和有差错时也这样做)
1.3 UDP 传输过程
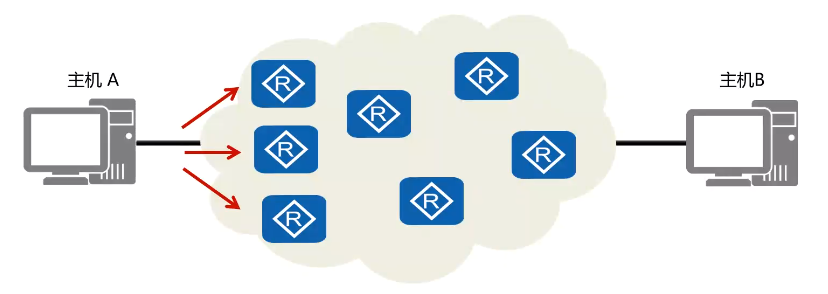
说明:
-
UDP传输数据包是以有序方式发送到网络,每个数据包独立在网络中被发送,也就是说先发送的数据包不一定先到,因为UDP数据包没有序号,需要应用程序提供报文到达确认,排序和流量控制等功能。通常情况下UDP采用实时传输机制和时间戳来传输语音和视频数据。
-
UDP不提供重传机制,占用资源小,处理效率高,一般处理一些时延敏感流量。如语音视频。
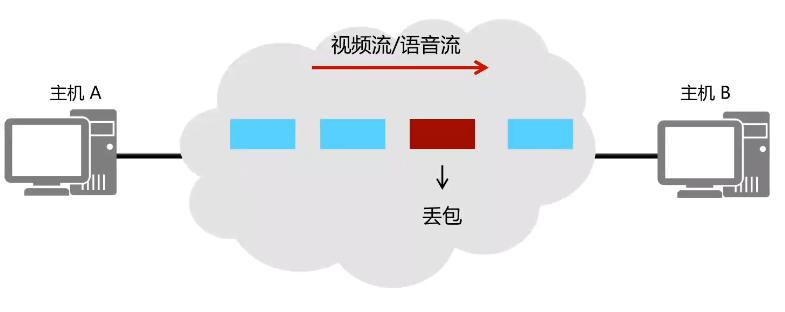
UDP数据包传输
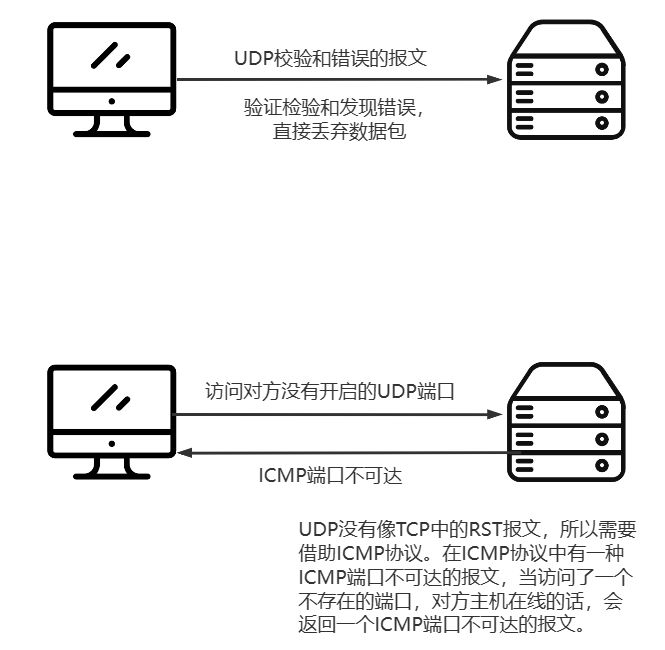
如果网络中出现了过多的ICMP端口不可达的报文,就需要注意参数端口不可达的原因,是因为内网的主机过度的访问了内网许多的UDP端口等等…
1.4 UDP-Lite
有些应用程序可以容忍发送和接受数据中存在比特差错,但是UDP使用的校验和会覆盖整个报文(或者不计算校验和),为了解决这个问题,UDP-Lite出现,提供部分负载和检验和计算方法。
- UDP-Lite是一个独立的协议,协议号为:136。
- UDP-Lite在UDP的基础上提供了一定程度的灵活性和容错能力。UDP-Lite允许在数据包传输过程中允许一定程度的数据损坏,而不会丢弃整个数据包。
- UDP-Lite的主要应用场景是对于那些对数据传输的实时性要求较高、对于一定程度的数据损坏能够容忍的应用程序。例如,音频和视频流传输、实时游戏等。通过UDP-Lite,这些应用程序可以在保持实时性的同时容忍一定程度的数据丢失或损坏,从而提高了用户体验。

UDP-Lite的校验和字段只检测部分的UDP内容。
UDP-Lite的工作原理如下:
- 发送方将数据分割成多个数据包,并为每个数据包计算校验和。
- 在发送数据包时,应用程序可以通过设置特定的服务类型字段来指定UDP-Lite协议。
- 接收方收到数据包后,会检查校验和。如果校验和无误,则数据包被认为是完好的,并传递给上层应用程序。
- 如果校验和出现错误,接收方会根据应用程序的要求决定是否接受该数据包并传递给上层应用程序。接收方可以根据自身需求调整对数据损坏的容忍程度。
- 对于被接受的损坏数据包,接收方可以对其进行进一步的处理,如尝试修复数据或仅使用可用的部分数据。
1.5 最大 UDP 数据报长度
- IP数据报的最大长度是65535字节,这是由IP首部16比特总长度字段所限制的。
- 遇到的两个限制因素。第一,应用程序可能会受到其程序接口的限制。socket API提供了一个可供应用程序调用的函数,以设置接收和发送缓存的长度。对于UDP socket,这个长度与应用程序可以读写的最大UDP数据报的长度直接相关。现在的大部分系统都默认提供了可读写大于8192字节的UDP数据报(使用这个默认值是因为8192是NFS读写用户数据数的默认值)。
- 第二个限制来自于TCP/IP的内核实现。可能存在一些实现特性(或差错),使IP数据报长度小于65535字节。
- 在Sn0S 4.1.3下使用环回接口的最大IP数据报长度是32767字节。比它大的值都会发生差错。但是从BSD/386到SuOS4.1.3的情况下,Sun所能接收到最大IP数据报长度为3278字节(即32758字节用户数据)。在Solars 2.2下使用环回接口,最大可收发IP数据报长度为65535字节。从Solaris2.2到AIX 3.2.2,发送的最大IP数据报长度可以是65535字节。很显然,这个限制与源端和目的端的实现有关。
- 主机必须能够接收最短为576字节的IP数据报。在许多UDP应用程序的设计中,其应用程序数据被限制成512字节或更小,因此比这个限制值小。
1.6 UDP 输入队列

UDP输入队列是指操作系统内核中专门用于存储待处理UDP数据包的缓冲区。当一台主机收到传入的UDP数据包时,这些数据包会首先被放置在UDP输入队列中。然后,相应的应用程序可以从队列中读取数据包并进行处理。
UDP输入队列的大小可能会受到操作系统内核参数的限制(上图中设置为256),通常以数据包数量或者内存大小为单位。如果UDP输入队列已满,新到达的UDP数据包可能会丢失,导致数据丢失和网络通信问题。
如上图所示最先抵达服务器的是1和4,是因为缓存不够,其他数据报直接被丢掉了。
补充:
- 大多数的系统在某一时刻只允许一个程序端点与某个本地IP地址及UDP端口号相关联。当目的地为该IP地址及端口号的UDP数据报到达主机时,就复制一份传给该端点。