文章目录
- 一.背景及导言
- 二.协议栈架构设计
- 1. 数据包接收和发送引擎
- 2. 协议解析
- 3. 数据包处理逻辑
- 三.网络函数编写
- 1.socket
- 2.bind
- 3.recvfrom
- 4.sendto
- 5.close
- 四.总结
一.背景及导言
在当今数字化的世界中,网络通信的高性能和低延迟对于许多应用至关重要。而用户态网络协议>网络协议栈通过摆脱传统内核态协议栈的限制,为实现更快速、灵活的数据包处理提供了新的可能性。本文将深入探讨基于DPDK的用户态UDP网络协议>网络协议栈的设计、实现。
传统的内核态协议栈在处理网络通信时通常伴随着较大的性能开销,而用户态网络协议>网络协议栈的崛起为高性能应用带来了全新的解决方案。DPDK,作为一款用于高性能数据平面应用的工具包,为用户态网络协议>网络协议栈的实现提供了强大的支持。通过将网络协议>网络协议栈移植到用户态,我们可以更灵活地优化数据包处理、提高吞吐量,并有效降低处理延迟。
二.协议栈架构设计
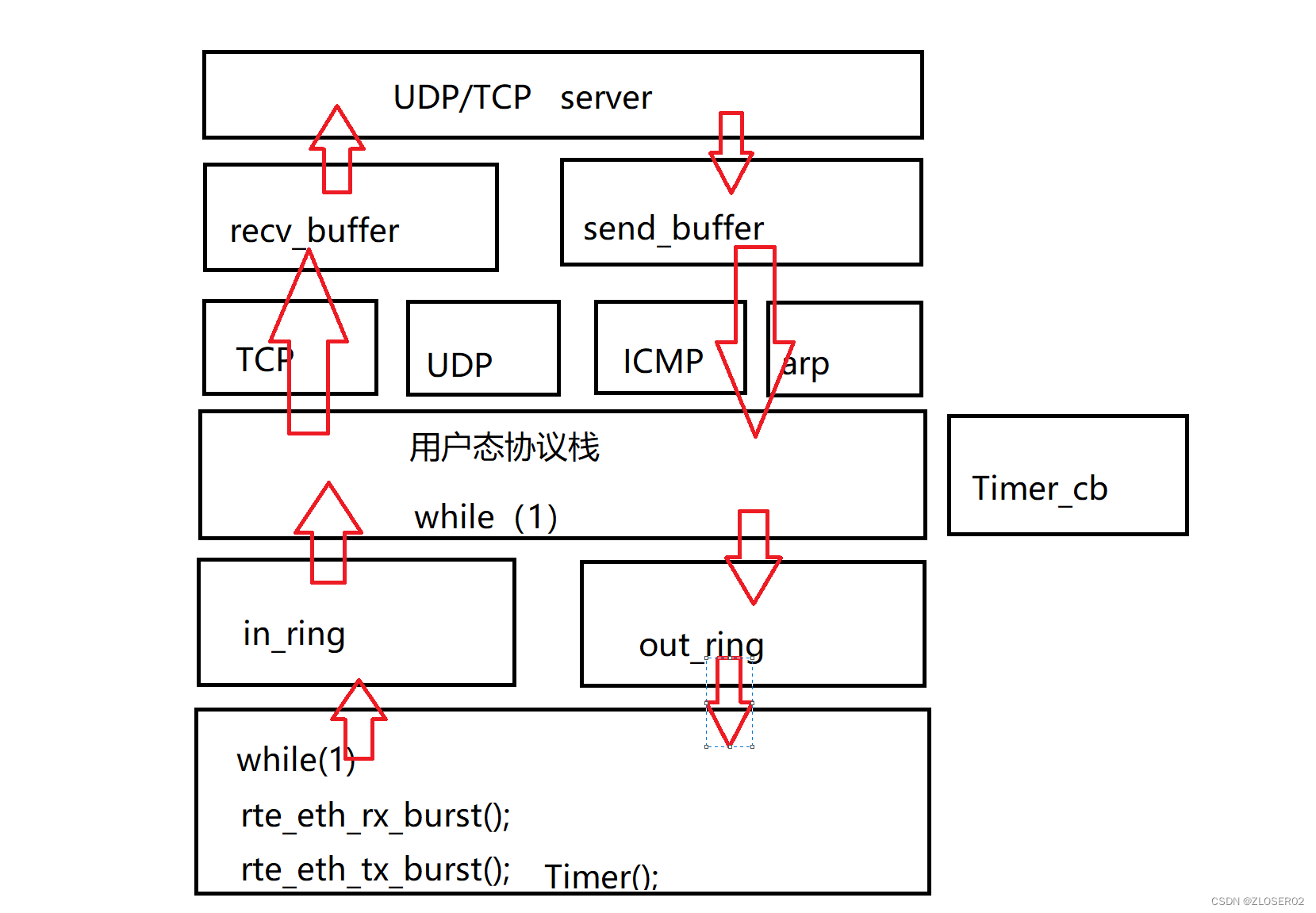
1. 数据包接收和发送引擎
数据包接收和发送引擎负责从网络接口接收数据包,并将数据包发送到目标地址。通过DPDK提供的高性能数据包I/O接口,实现对多队列的支持,以提高并行性和吞吐量。
从网卡接收原始数据放入in_ring:
rte_eth_rx_burst();
从out_ring中取出数据通过网卡发送:
rte_eth_tx_burst();
while(1) {
// rx
struct rte_mbuf *rx[BURST_SIZE];// 内存池
//接收
unsigned num_recvd = rte_eth_rx_burst(gDpdkPortId, 0, rx, BURST_SIZE);
if(num_recvd > BURST_SIZE) {
rte_exit(EXIT_FAILURE, "Error receiving from eth\n");
} else if(num_recvd > 0) {
//入队列
rte_ring_sp_enqueue_burst(ring->in, (void**)rx, num_recvd, NULL);
}
// tx
struct rte_mbuf *tx[BURST_SIZE];
//出队列
unsigned nb_tx = rte_ring_sc_dequeue_burst(ring->out, (void**)tx, BURST_SIZE,NULL);
if(nb_tx > 0) {
//发送
rte_eth_tx_burst(gDpdkPortId, 0, tx, nb_tx);
unsigned i = 0;
for(;i < nb_tx; i++) {
rte_pktmbuf_free(tx[i]);
}
}
static uint64_t prev_tsc = 0, cur_tsc;
uint64_t diff_tsc;
cur_tsc = rte_rdtsc();
diff_tsc = cur_tsc - prev_tsc;
if(diff_tsc > TIMER_RESOLUTION_CYCLES) {
rte_timer_manage();
prev_tsc = cur_tsc;
}
}
2. 协议解析
协议解析模块负责对接收到的UDP数据包进行解析,提取出源和目标端口号、校验和等关键信息。采用高效的解析算法,确保对数据包的处理不成为性能瓶颈。
从原始数据包中解析以太网头:
struct rte_ether_hdr *ehdr = rte_pktmbuf_mtod(mbufs[i],struct rte_ether_hdr*);
从原始数据包中(偏移以太网头)解析arp头:
struct rte_arp_hdr *ahdr = rte_pktmbuf_mtod_offset(mbufs[i],struct rte_arp_hdr *,
sizeof(struct rte_ether_hdr));
从原始数据包中解析IP头:
struct rte_ipv4_hdr *iphdr = rte_pktmbuf_mtod_offset(mbufs[i], struct rte_ipv4_hdr *,
sizeof(struct rte_ether_hdr));
通过IP头中的网络类型协议可以得知该数据包是UDP,TCP或ICMP包,通过类型强制转换可以得到相对应的数据包协议头。
通过IP头偏移1位强转可得到UDP/TCP头:
struct rte_udp_hdr *udphdr = (struct rte_udp_hdr *)(iphdr + 1);
通过IP头偏移1位强转可得到ICMP头:
struct rte_icmp_hdr *icmphdr = (struct rte_icmp_hdr *)(iphdr + 1);
不同的数据包调用不同的函数处理,通过对数据包的解析可以得到我们想要的IP地址,端口号,以太网地址,数据等。
3. 数据包处理逻辑
数据包处理逻辑包括各种应用层的逻辑,如数据包过滤、路由决策等。这一部分需要具体根据应用场景进行定制,以满足不同需求。
当用户接收并处理完数据包后得到新的用户数据需要发送,此时我们只需要逆向操作接收数据包的过程即可。
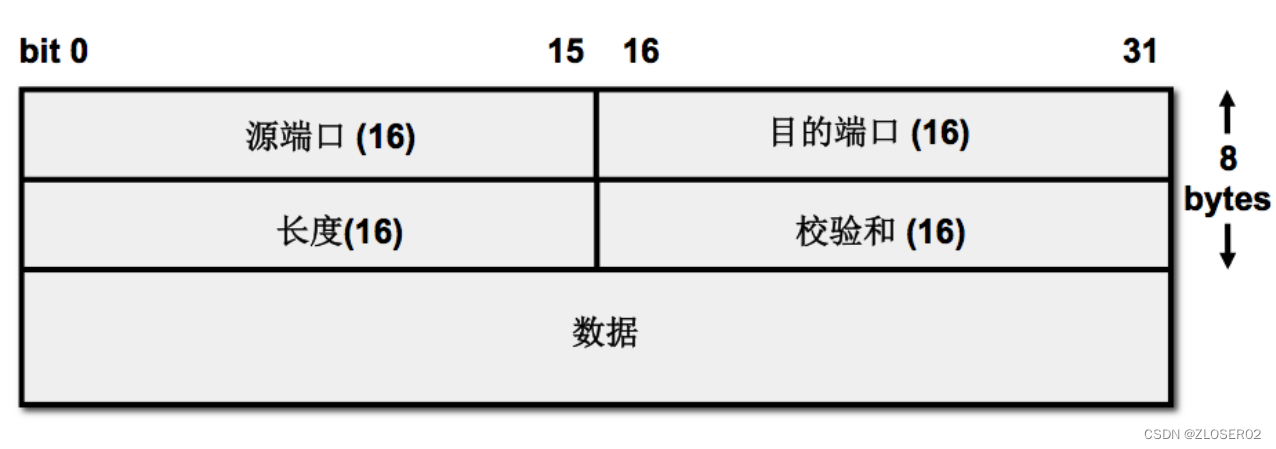
一个UDP数据帧组成结构如图所示,在用户数据上添加UDP头,在此基础上再添加IP头,最后再添加以太网头,一个UDP数据帧就组装完毕,就可直接通过网卡发送。
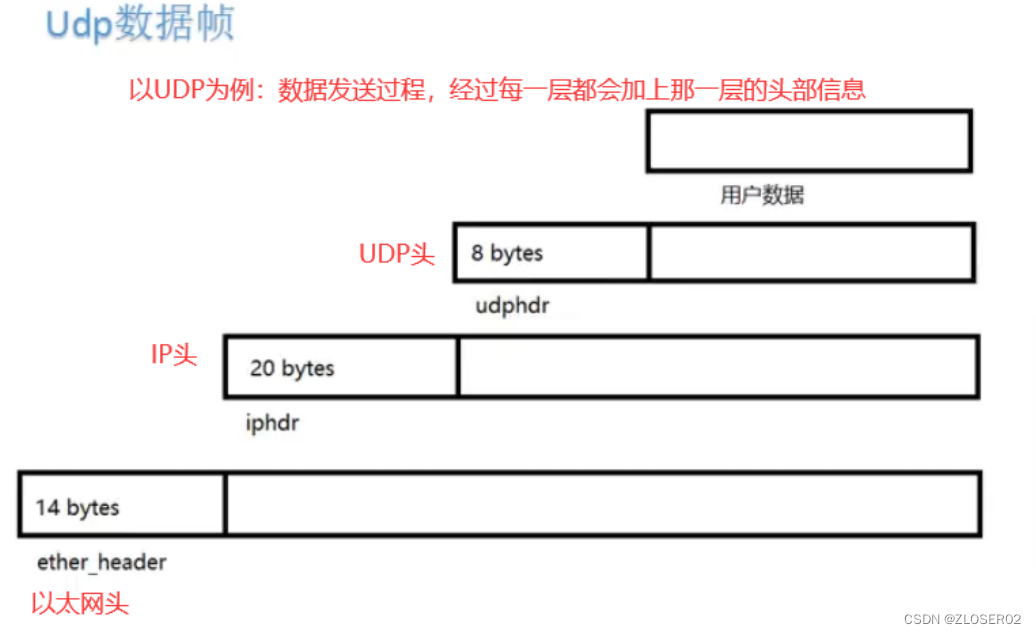
按UDP数据帧结构从用户数据从上往下依次组包。

!](https://img-blog.csdnimg.cn/direct/ede89757233f4dca8eff2eec63826075.png)
//1 ether
struct rte_ether_hdr *eth = (struct rte_ether_hdr*)msg;
rte_memcpy(eth->s_addr.addr_bytes, src_mac, RTE_ETHER_ADDR_LEN);//源Mac地址
rte_memcpy(eth->d_addr.addr_bytes, dst_mac, RTE_ETHER_ADDR_LEN);//目的Mac地址
eth->ether_type = htons(RTE_ETHER_TYPE_IPV4);//类型
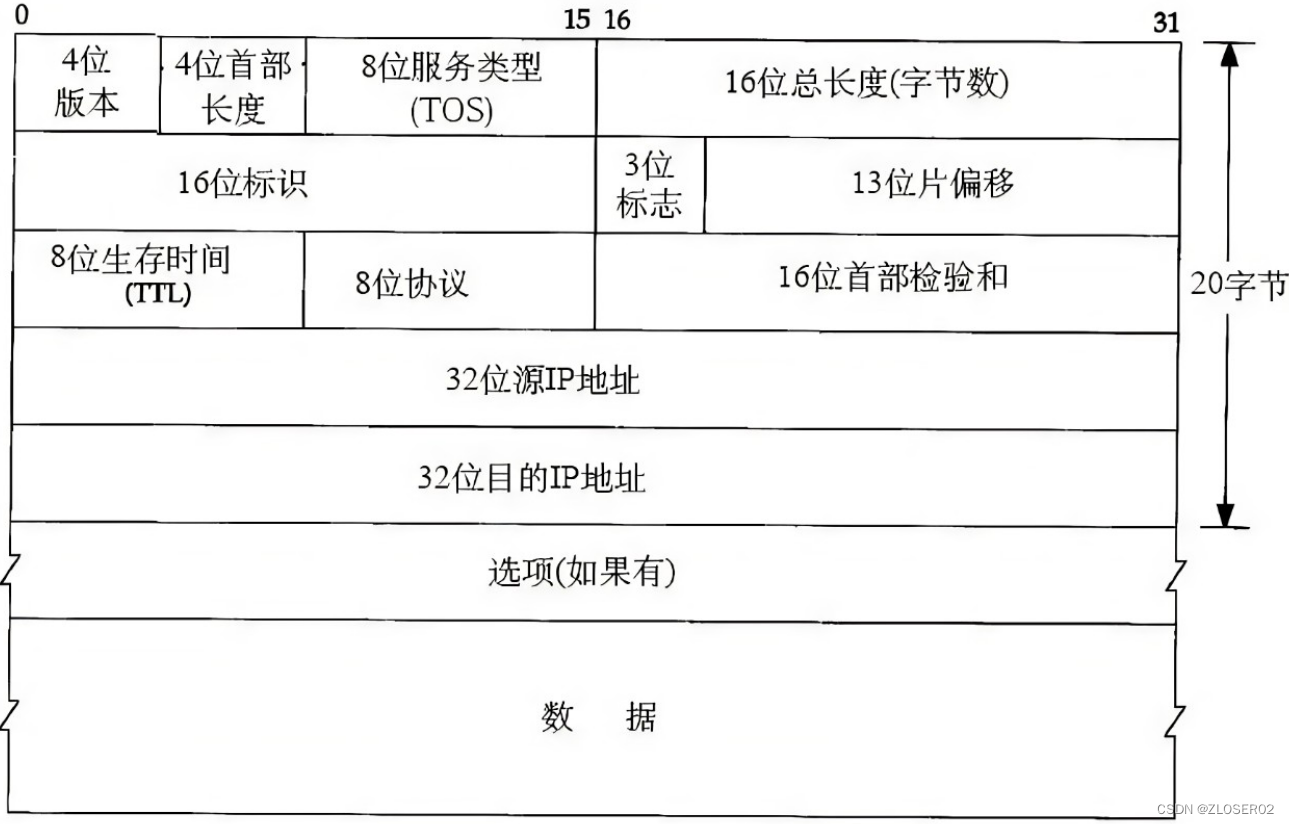
//2 iphdr
struct rte_ipv4_hdr *ip = (struct rte_ipv4_hdr*)(msg + sizeof(struct rte_ether_hdr));
ip->version_ihl = 0x45; //4位版本,4位首部长度
ip->type_of_service = 0;//服务类型
ip->total_length = htons(length - sizeof(struct rte_ether_hdr));//总长度
ip->packet_id = 0;//16位标识
ip->fragment_offset = 0;//偏移
ip->time_to_live = 64; //TTL
ip->next_proto_id = IPPROTO_UDP;//8位协议
ip->src_addr = sip;
ip->dst_addr = dip;
ip->hdr_checksum = 0;
ip->hdr_checksum = rte_ipv4_cksum(ip);//首部校验和
//3 udp
struct rte_udp_hdr *udp = (struct rte_udp_hdr*)(msg + sizeof(struct rte_ether_hdr) + sizeof(struct rte_ipv4_hdr));
udp->src_port = sport;//源端口
udp->dst_port = dport;//目的端口
uint16_t udplen = length - sizeof(struct rte_ether_hdr) - sizeof(struct rte_ipv4_hdr);
udp->dgram_len = htons(udplen);//长度
rte_memcpy((uint8_t*)(udp + 1), data, udplen);
udp->dgram_cksum = 0;
udp->dgram_cksum = rte_ipv4_udptcp_cksum(ip, udp);//校验和
所有数据包都有以太网头,IP头和arp头为第二层,TCP UDP ICMP为第三次,数据组包的时候只需根据需求选择不同的协议填空即可。
三.网络函数编写
定义主机,包括:唯一标识符,IP地址,Mac地址,协议,recvbuf,senfbuf,互斥锁,条件变量,链表结构。
struct localhost {
int fd;
uint32_t localip;
uint8_t localmac[RTE_ETHER_ADDR_LEN];
uint16_t localport;
uint8_t protocol;
struct rte_ring *recvbuf;
struct rte_ring *sendbuf;
struct localhost *prev;
struct localhost *next;
pthread_cond_t cond;
pthread_mutex_t mutex;
};
static struct localhost *lhost = NULL;
1.socket
static int
socket(__attribute__((unused))int domain, int type, __attribute__((unused))int protocol) {
int fd = get_fd_frombitmap();
struct localhost *host = rte_malloc("localhost", sizeof(struct localhost), 0);
if(host == NULL) {
return -1;
}
memset(host, 0, sizeof(struct localhost));
host->fd = fd;
if(type == SOCK_DGRAM) {
host->protocol = IPPROTO_UDP;
}
host->recvbuf = rte_ring_create("recv buf",RING_SIZE,rte_socket_id(),RING_F_SP_ENQ | RING_F_SC_DEQ);
if(host->recvbuf == NULL) {
rte_free(host);
return -1;
}
host->sendbuf = rte_ring_create("send buf",RING_SIZE,rte_socket_id(),RING_F_SP_ENQ | RING_F_SC_DEQ);
if(host->sendbuf == NULL) {
rte_ring_free(host->recvbuf);
rte_free(host);
return -1;
}
pthread_cond_t blank_cond = PTHREAD_COND_INITIALIZER;
rte_memcpy(&host->cond, &blank_cond, sizeof(pthread_cond_t));
pthread_mutex_t blank_mutex = PTHREAD_MUTEX_INITIALIZER;
rte_memcpy(&host->mutex, &blank_mutex, sizeof(pthread_mutex_t));
LL_ADD(host, lhost);
return fd;
}
2.bind
static int bind(int sockfd, const struct sockaddr *addr,__attribute__((unused))socklen_t addrlen) {
struct localhost *host = get_hostinfo_fromfd(sockfd);
if(host == NULL) {
return -1;
}
const struct sockaddr_in *laddr = (const struct sockaddr_in*)addr;
host->localport = laddr->sin_port;
rte_memcpy(&host->localip, &laddr->sin_addr.s_addr, sizeof(uint32_t));
rte_memcpy(host->localmac, gSrcMac, RTE_ETHER_ADDR_LEN);
return 0;
}
3.recvfrom
static ssize_t recvfrom(int sockfd, void *buf, size_t len, __attribute__((unused))int flags,
struct sockaddr *src_addr, __attribute__((unused))socklen_t *addrlen){
struct localhost *host = get_hostinfo_fromfd(sockfd);
if(host == NULL) return -1;
struct sockaddr_in *saddr = (struct sockaddr_in*)src_addr;
//dequeue
struct offload *ol = NULL;
unsigned char *ptr = NULL;
int nb = -1;
//阻塞
pthread_mutex_lock(&host->mutex);
while((nb = rte_ring_mc_dequeue(host->recvbuf,(void**)&ol)) < 0) {
pthread_cond_wait(&host->cond, &host->mutex);
}
pthread_mutex_unlock(&host->mutex);
saddr->sin_port = ol->sport;
rte_memcpy(&saddr->sin_addr.s_addr, &ol->sip, sizeof(uint32_t));
struct in_addr addr;
addr.s_addr = ol->dip;
printf("nrecvto ---> src: %s:%d \n", inet_ntoa(addr), ntohs(ol->dport));
if(len < ol->length) { //一次无法接收全部数据
rte_memcpy(buf, ol->data, len);
ptr = rte_malloc("unsigned char *", ol->length - len, 0);
rte_memcpy(ptr, ol->data + len, ol->length - len);
ol->length -= len;
rte_free(ol->data);
ol->data = ptr;
rte_ring_mp_enqueue(host->recvbuf, ol);
return len;
} else {
rte_memcpy(buf, ol->data, ol->length);
rte_free(ol->data);
rte_free(ol);
return ol->length;
}
}
4.sendto
static ssize_t sendto(int sockfd, const void *buf, size_t len, __attribute__((unused))int flags,
const struct sockaddr *dest_addr, __attribute__((unused))socklen_t addrlen){
struct localhost *host = get_hostinfo_fromfd(sockfd);
if(host == NULL) return -1;
const struct sockaddr_in *daddr = (const struct sockaddr_in*)dest_addr;
struct offload *ol = rte_malloc("offload", sizeof(struct offload), 0);
if(ol == NULL) {
return -1;
}
ol->dip = daddr->sin_addr.s_addr;
ol->dport = daddr->sin_port;
ol->sip = host->localip;
ol->sport = host->localport;
ol->length = len;
struct in_addr addr;
addr.s_addr = ol->dip;
printf("nsendto ---> src: %s:%d \n", inet_ntoa(addr), ntohs(ol->dport));
ol->data = rte_malloc("ol data", len, 0);
if(ol->data == NULL) {
rte_free(ol);
return -1;
}
rte_memcpy(ol->data, buf, len);
rte_ring_mp_enqueue(host->sendbuf, ol);
return len;
}
5.close
static int nclose(int fd) {
struct localhost *host = get_hostinfo_fromfd(fd);
if(host == NULL) {
return -1;
}
LL_REMOVE(host, lhost);
if(host->recvbuf){
rte_ring_free(host->recvbuf);
}
if(host->sendbuf){
rte_ring_free(host->sendbuf);
}
rte_free(host);
return 0;
}
四.总结
通过本文,我们深入研究了基于DPDK的用户态UDP网络协议>网络协议栈的设计、实现。在整体设计思路上,我们采用了用户态网络协议>网络协议栈的理念,通过将核心功能移至用户空间,结合DPDK的强大支持,实现了一个高性能、低延迟的数据包处理方案。
关键组成部分中,我们详细介绍了数据包接收和发送引擎、协议解析、数据包处理逻辑等模块。这些组成部分共同协作,使得用户态UDP网络协议>网络协议栈能够在不同应用场景下发挥其优势。
整体架构图清晰展示了各个模块之间的关系,以及数据在协议栈中的流动路径。这有助于读者更好地理解我们设计的用户态UDP网络协议>网络协议栈的整体结构。
通过对用户态UDP网络协议>网络协议栈的研究,我们不仅深刻理解了其设计和实现,也为构建更高性能、更灵活的网络通信系统奠定了基础。未来,我们期待在这一基础上进一步优化和扩展,以满足不断发展的网络应用需求。

![[ISP]DCT离散余弦变换及C++代码demo](https://img-blog.csdnimg.cn/direct/e6492ecaa33640fcb1c3433a7538028f.png)