前言: \textcolor{Green}{前言:} 前言:
💞这个专栏就专门来记录一下寒假参加的第五期字节跳动训练营
💞从这个专栏里面可以迅速获得Go的知识
微服务架构介绍2
- 3 核心服务治理功能
- 3.1 服务发布
- 3.2 流量治理
- 3.3 负载均衡
- 3.4 稳定性治理
- 4. 字节跳动服务治理实践
- 4.1 重试的意义
- 4.2 重试的难点
- 4.3 重试策略
- 4.4 重试效果验证
3 核心服务治理功能
3.1 服务发布
服务发布(deployment),即指让一个服务升级运行新的代码的过程。
服务发布的难点:
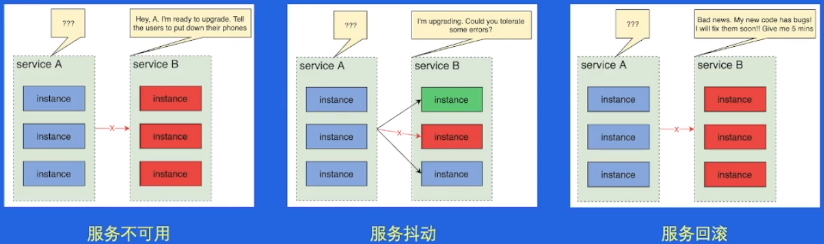
蓝绿部署
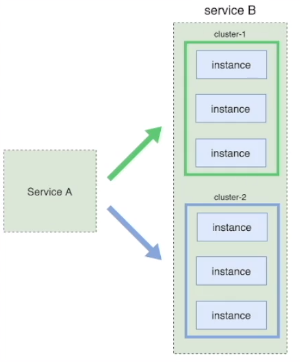
(1)需要准备两个相同的应用运行环境,命名为蓝色环境、绿色环境,刚开始,蓝色环境和绿色环境都运行着相同的应用版本,只有绿色环境对外提供服务。
(2)开发了一个新版本,那么放到蓝色环境上进行反复的测试、修改、验证,确定达到上线标准后,利用负载均衡器/反向代理/路由等手段将对外服务切换为蓝色环境。
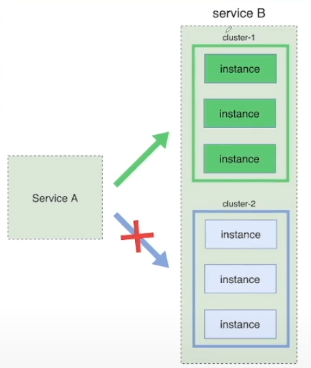
(3)一段时间后,如果发生故障,那么迅速切换回绿色环境;如果运行没有异常,那么绿色环境更新版本到,版本再次一致。
(4)当需要开发下一个版本,重复前面的步骤,蓝色绿色相互切换相互备份。
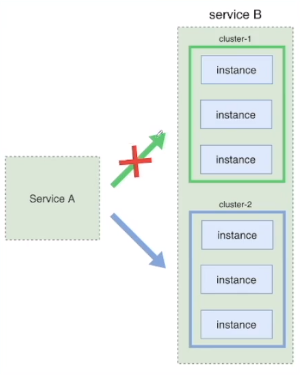

再次同样的步骤
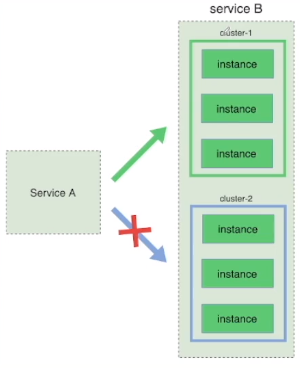
蓝绿部署非常的简单、稳定。但是需要双倍的资源

灰度发布(金丝雀发布)
金丝雀(canary)对瓦斯极其敏感,17世纪时,英国矿工在下井前会先放入一只金丝雀,以确保矿井中没有瓦斯
回滚难度大,基础设施要求高
3.2 流量治理
在微服务架构下,我们可以基于地区、集群、实例、请求等维度,对端到端流量的路由路径进行精确控制。
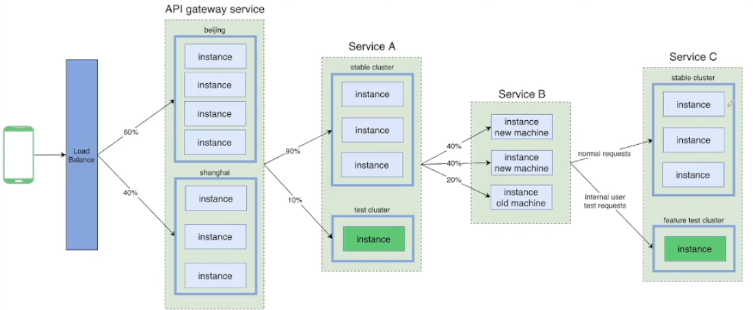
用了多种分类进行区分。
这里指的是侠义的对流量进行控制
3.3 负载均衡
负载均衡(Load Balance)负责分配请求在每个下游实例上的分布
常见的 LB 策略
- Round Robin
- Random
- Ring Hash
- Least Request
- …
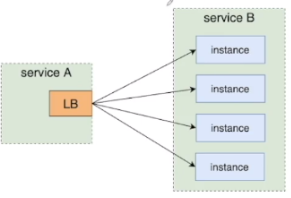
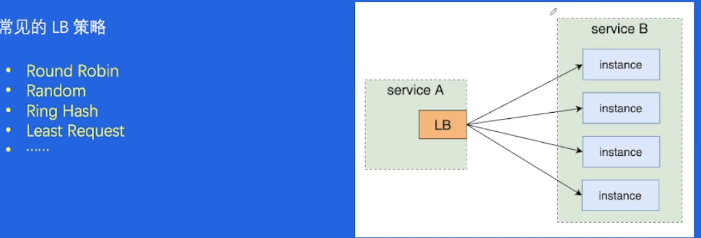
一个服务中,通常每个实例的负载应是大体均衡一致的。
3.4 稳定性治理
线上服务总是会出现问题的,这与程序的正确性无关。例如:
- 网络攻击
- 流量突增
- 机房断电
- 光纤被挖
- 机器故障
- 网络故障
- 机房空调故障
- …
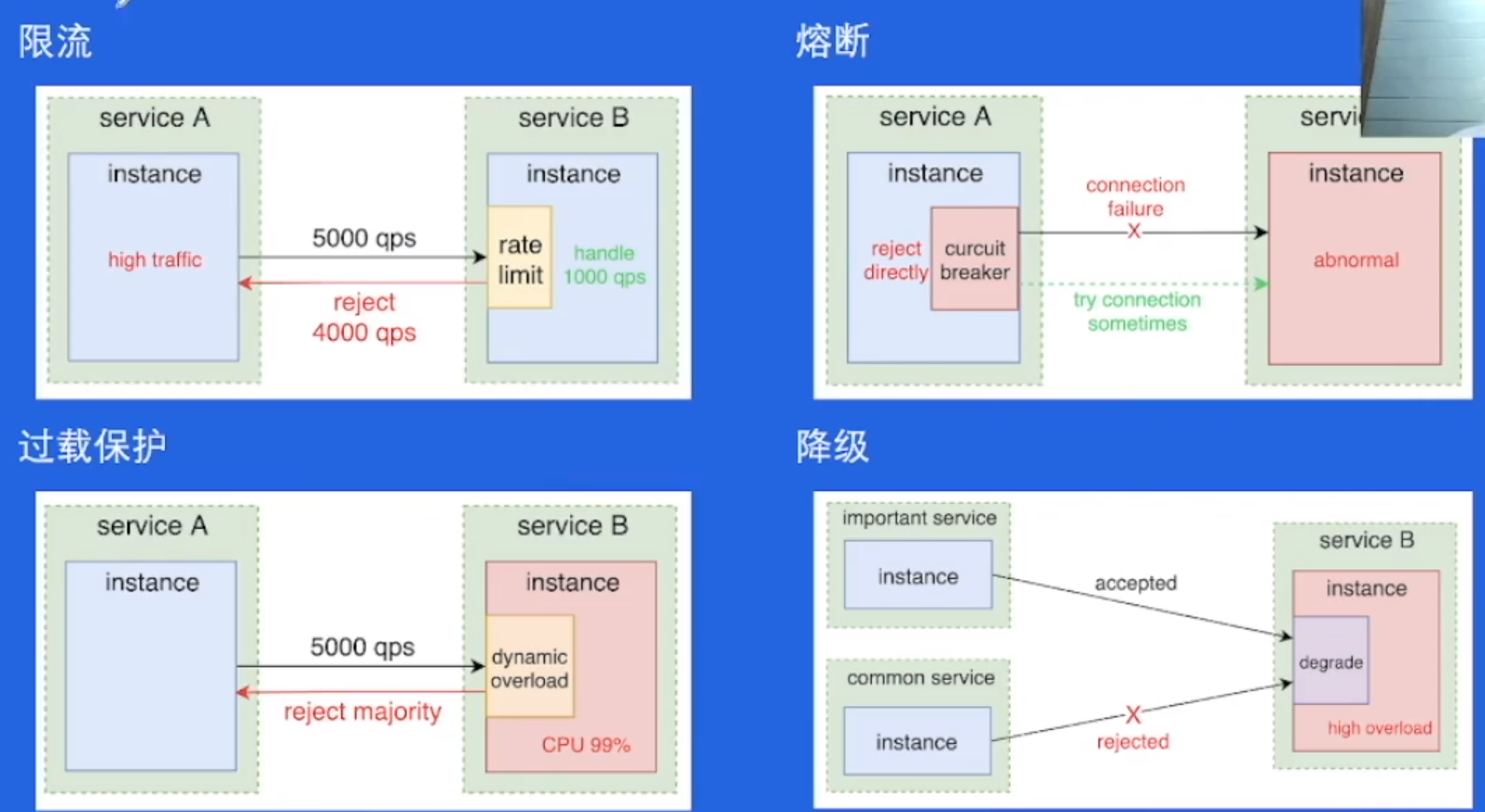
- 限流
- 熔断
- 过载保护
- 降级
4. 字节跳动服务治理实践
4.1 重试的意义
本地函数调用
func LocalFunc(x int) int {
res := calculate(x - 2)
return res
}
此时我们因本地函数嗲用发现
- 参数非法
- OOM(Out Of Memeory)
- NPE(Null Pointer Exception)
- 边界 case
- 系统崩溃
- 死循环
- 程序异常退出
需要明白:本地函数调用没有重试的意义
远程函数调用
fun RemoteFunc(ctx context.Context, x int) (int, error) {
ctx2, defer_func := context.WithTimeout(ctx, time.Second)
defer defer_func()
res, err := grpc_client.Calculate(ctx2, x - 2)
return res, err
}
远程调用会的异常:
- 网络抖动
- 下载负载高导致超时
- 下游机器宕机
- 本地机器负载高,调度超时
- 下游熔断、限流
- …
重试可以避免偶发的错误,提高SLA(Service-Level Agreement)
fun RemoteFunc(ctx context.Context, x int) (int, error) {
ctx2, defer_func := context.WithTimeout(ctx, time.Second)
defer defer_func()
res, err := grpc_client.Calculate(ctx2, x - 2)
return res, err
}
fun RemoteFuncRetry(ctx context.Context, x int) (res int, err error) {
for i := 0; i < 3; i++ {
if res, err = RemoteFunc(ctx, x); err == nil {
return
}
}
return
}
此时我们就知道重试的意义
- 降低错误率
- 假设单次请求的错误概率为 0.01,那么连续两次错误概率为 0.0001。
- 降低长尾延时
- 对于偶尔耗时较长的请求,重试请求有机会提前返回。
- 容忍暂时性错误
- 某些时候系统会有暂时性异常(例如网络抖动),重试可以尽量规避。
- 避开下游故障实例
- 一个服务中可能会有少量实例故障(例如机器故障),重试其他实例可以成功。
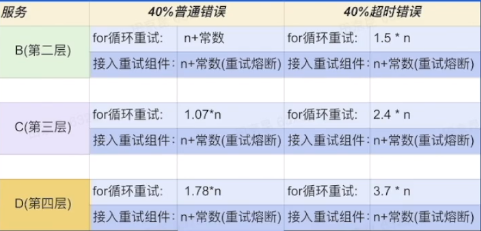
4.2 重试的难点
既然重试的好处有很多,为什么默认不用呢?
这是因为:
- 幂等性:多次请求可能导致数据不一致
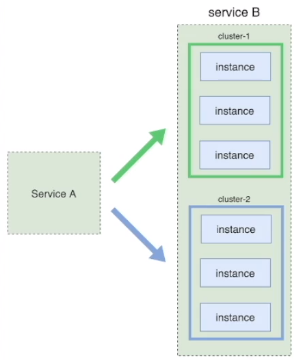
- 重试风暴:随着调用深度的增加,重试次数会指数级上涨
- 超时设置:假设一个调用正常是 1s 的超时时间,如果允许一次重试。有个问题:如果第一次请求经过多少时间时,才开始重试呢?
重试风暴
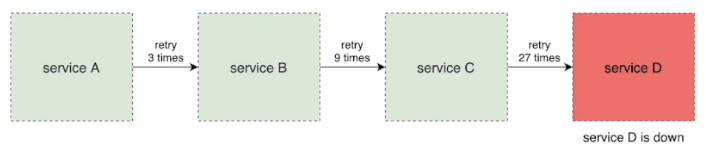
4.3 重试策略
重试只有在大部分请求都成功,只有少量请求失败时,才有必要。如果大部分请求都失败,重试只会增加问题严重性。
-
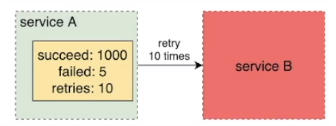
限制重试比例
设定一个重试比例阈值(例如 1%)。重试次数占所有请求比例不超过该阈值
-
防止链路重试
链路层面的防重试风暴的核心是限制每层都发生重试,理想情况下只有最下一层发生重试。可以返回特殊的 status 表明:“请求失败,但别重试”

缺点:对业务代码有侵入性 -
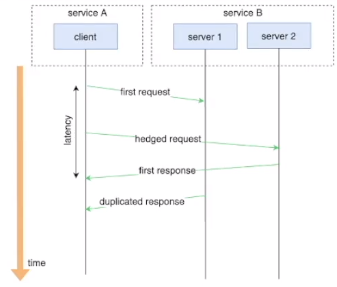
Hedged requests
对于可能超时(或延时高)的请求,重新向另一个下游实例发送一个相同的请求,并等待先到达的响应。
4.4 重试效果验证
实际验证经过上述重试策略后,在链路上发生的重试放大效应。