论文地址:https://arxiv.org/abs/1904.04971
代码地址:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet/condconv
1.是什么?
CondConv是一种条件参数卷积,也称为动态卷积,它是一种即插即用的模块,可以为每个样例学习一个特定的卷积核参数。通过替换标准卷积,CondConv可以提升模型的尺寸与容量,同时保持高效推理。CondConv的设计优越性在于它只需要做一次卷积,而不像其他方法需要做n次卷积,这样可以大大减少计算开销。CondConv可以对现有网络中的标准卷积进行替换,同时适用于深度卷积与全连接层。实验结果表明,CondConv可以显著提高模型的性能。
2.为什么?
CNN在诸多计算机视觉任务中取得了前所未有的成功,但其性能的提升更多源自模型尺寸与容量的提升以及更大的数据集。模型的尺寸提升进一步加剧了计算量的提升,进一步加大优秀模型的部署难度。
现有CNN的一个基本假设:对所有样例采用相同的卷积参数。这就导致:为提升模型的容量,就需要加大模型的参数、深度、通道数,进一步导致模型的计算量加大、部署难度提升。由于上述假设以及终端部署需求,当前高效网络往往具有较少的参数量。然而,在某些计算机视觉应用中(如终端视频处理、自动驾驶),模型实时性要求高,对参数量要求较低。
作者提出一种条件参数卷积用于解决上述问题,它通过输入计算卷积核参数打破了传统的静态卷积特性。特别的,作者将CondConv中的卷积核参数化为多个专家知识的线性组合(其中,是通过梯度下降学习的加权系数):。为更有效的提升模型容量,在网络设计过程中可以提升专家数量,这比提升卷积核尺寸更为高效,同时专家知识只需要进行一次组合,这就可以在提升模型容量的同时保持高效推理。
3 怎么样?
3.1网络结构

结构1,如下图,首先它采用更细粒度的集成方式,每一个卷积层都拥有多套权重,卷积层的输入分别经过不同的权重卷积之后组合输出,缺点是但这计算量依旧很大。

结构2,如图2,为了解决图1计算大问题,作者提出既然输入相同,卷积是一种线性计算,COMBINE也是一个线性计算(比如加权求和),作者将多套权重加权组合之后,只做一次卷积就能完成相当的效果!计算量相比上图,大大降低。
3.2 原理
在常规卷积中,其卷积核参数经训练确定且对所有输入样本“一视同仁”;而在CondConv中,卷积核参数参数通过对输入进行变换得到,该过程可以描述为:

这里x xx表示上一个layer的输出,n nn表示这一层Condconv Layer有n nn个expert(expert就是该层的卷积核W),σ 表示激活函数,表示一个样本依赖的加权参数。
所以一个CondConv层的卷积核参数的由来,就是通过上述的线性组合公式。整个流程可以概括为:依赖于输入x,在卷积操作之前,通过routing函数计算出每一个expert前面的系数
,再通过线性组合,得到CondConv层最终的kernal,最后与输入x xx做卷积,并进行activation。在这里,routing weight的计算公式如下:
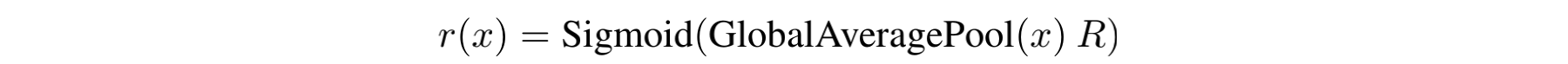
对于输入x xx,首先做GlobalAveragePooling,随后右乘一个矩阵R(该矩阵的目的是将维度映射到n个expert上面,以实现后续的线性组合),最后通过sigmoid将每一个维度上的权值规约到[0,1]区间。因此,根据输入x xx的不同,就会得到不同的routing weight向量,进而CondConv层的kernal也各有差异。
3.3代码实现
python">import torch
import torch.nn.functional as F
import torch.nn as nn
from torch import Tensor
import functools
from torch.nn.modules.conv import _ConvNd
from torch.nn.modules.utils import _pair
from torch.nn.parameter import Parameter
class _routing(nn.Module):
def __init__(self, in_channels, num_experts, dropout_rate):
super(_routing, self).__init__()
self.dropout = nn.Dropout(dropout_rate)
self.fc = nn.Linear(in_channels, num_experts)
def forward(self, x):
x = torch.flatten(x)
x = self.dropout(x)
x = self.fc(x)
return F.sigmoid(x)
class CondConv2D(_ConvNd):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1,
bias=True, padding_mode='zeros',
num_experts=3, dropout_rate=0.2):
# tuple
kernel_size = _pair(kernel_size)
stride = _pair(stride)
padding = _pair(padding)
dilation = _pair(dilation)
super(CondConv2D, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
False, _pair(0), groups, bias, padding_mode)
self._avg_pooling = functools.partial(F.adaptive_avg_pool2d, output_size=(1, 1))
self._routing_fn = _routing(in_channels, num_experts, dropout_rate)
self.weight = Parameter(torch.Tensor(
num_experts, out_channels, in_channels // groups, *kernel_size))
self.reset_parameters()
def _conv_forward(self, input, weight):
if self.padding_mode != 'zeros':
return F.conv2d(F.pad(input, self._padding_repeated_twice, mode=self.padding_mode),
weight, self.bias, self.stride,
_pair(0), self.dilation, self.groups)
return F.conv2d(input, weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)
def forward(self, inputs):
b, _, _, _ = inputs.size()
res = []
for input in inputs:
input = input.unsqueeze(0)
pooled_inputs = self._avg_pooling(input)
routing_weights = self._routing_fn(pooled_inputs)
kernels = torch.sum(routing_weights[: ,None, None, None, None] * self.weight, 0)
out = self._conv_forward(input, kernels)
res.append(out)
return torch.cat(res, dim=0)参考:
动态卷积之CondConv和DynamicConv
CondConv:用于有效推理的条件参数化卷积