Pre-training a seq2seq model
BERT只是一个预训练Encoder,有没有办法预训练Seq2Seq模型的Decoder?
在一个transformer的模型中,将输入的序列损坏,然后Decoder输出句子被破坏前的结果,训练这个模型实际上是预训练一个Seq2Seq模型。

可以采用mass或BART手段损坏输入数据,mass是盖住某些数据(类似于masking),BART是综合了右边所有的方法(盖住数据、删除数据、打乱数据顺序、旋转词的顺序等等),BART的效果要比mass好。

Training BERT is challenging
目前要训练BERT难度很大,一方面是数据量庞大,处理起来很艰难;另一方面是训练的过程需要很长的时间。
谷歌最早的BERT,它使用的数据规模已经很大了,包含了30亿个词汇。BERT有一个base版本和一个large版本。对于大版本,我们很难自己训练它,所以我们尝试用最小的版本来训练,看它是否与谷歌的结果相同。横轴是训练过程,参数更新多少次,大约一百万次的更新,用TPU运行8天,如果你在Colab上做,这个至少要运行200天。在Colab上微调BERT只需要半小时到一小时
我们自己训练BERT后,可以观察到BERT什么时候学会填什么词汇,它是如何提高填空能力的? 论文的链接https://arxiv.org/abs/2010.02480
为什么pre-train的BERT会做填空题,微调一下就能用作其他的应用呢?
输入一串文本,每个文本都有一个对应的输出向量,这个向量称之为embedding,代表了输入词的含义。意思越相近的字产生的向量越接近,如图右部分。同时,BERT会根据上下文,不同语义的同一个字产生不同的embedding

下图中,根据 "苹果 "一词的不同语境,得到的向量会有所不同。计算这些结果之间的cosine similarity,即计算它们的相似度。计算每一对之间的相似度,得到一个10×10的矩阵。相似度越高,这个颜色就越浅。前五个 "苹果 "和后五个 "苹果 "之间的相似度相对较低。BERT知道,前五个 "苹果 "是指可食用的苹果,所以它们比较接近。最后五个 "苹果 "指的是苹果公司,所以它们比较接近。所以BERT知道,上下两堆 "苹果 "的含义不同
训练填空题BERT时,就是从上下文提取信息来填空,学会了每个汉字的
意思,也许它真的理解了中文,既然它理解了中文,在接下来的任务中只要微调即可。
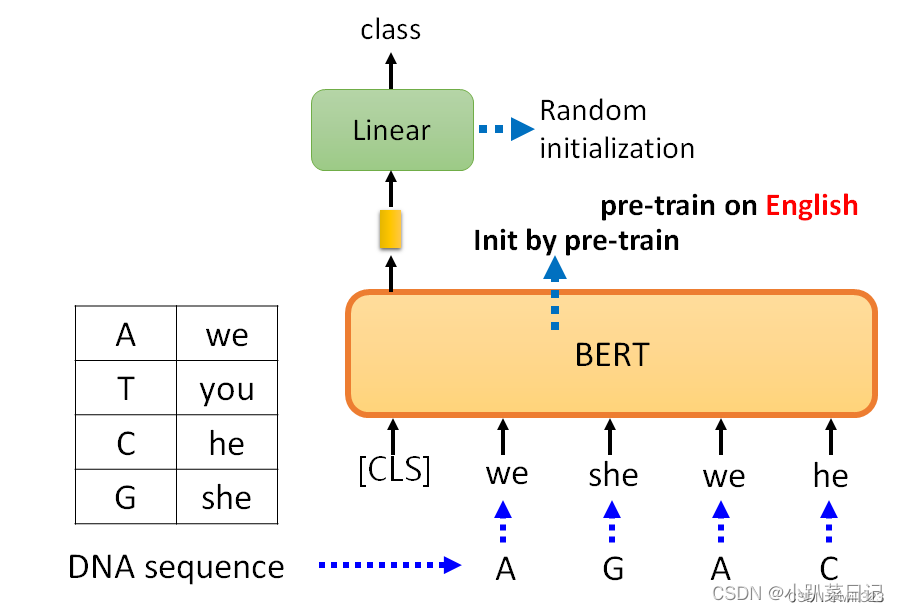
使用BERT分类蛋白质、DNA链
和以前一样,Linear classification使用随机初始化,而BERT是通过预训练模型得到的参数初始化的,它已经学会了英语填空。
DNA是一系列的脱氧核团核酸,有四种,分别用A、T、C和G表示。用BERT来对DNA进行分类,例如,"A "是 "we","T "是 "you","C "是 "he","G "是 "she"。例如,"AGAC "变成了 "we she we he",不知道它在说什么,这个英文句子没意义,所以即使你给BERT一个无意义的句子,它仍然可以很好地对句子进行分类。
蛋白质是由氨基酸组成的,有十种氨基酸,给每个氨基酸一个随机的词汇
如果不使用BERT,你得到的结果是蓝色部分,如果你使用BERT,你得到的结果是红色部分
 Multi-lingual BERT(多语言BERT)
Multi-lingual BERT(多语言BERT)
Multi-lingual BERT是用许多不同的语言预训练的BERT。fine-tune是训练时输入的语言,test是测试时输入问题和文章的语言。
如果把一个Multi-lingual的BERT用英文问答数据进行微调,它就会自动学习如何做中文问答,有78%的正确率。BERT在预训练中学到了英文填空和中文填空,在微调中学到了做英文问答。 但BERT未接受过中文和英文之间的翻译训练,也从未用中文问答数据进行微调,就自动学会了做中文问答

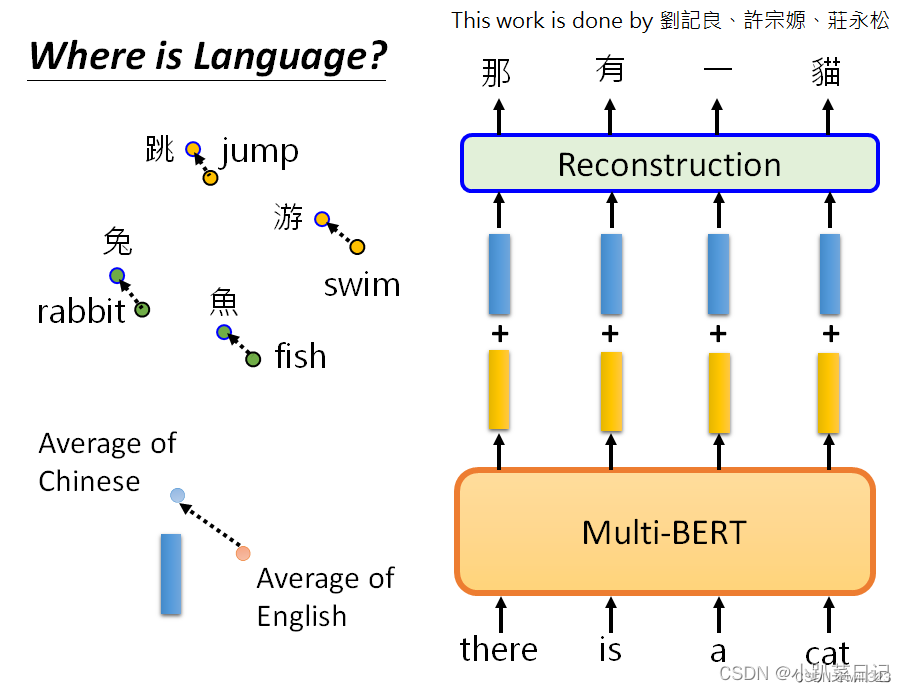
为什么会自动学会呢?一个简单的解释是:也许对于多语言的BERT来说,不同的语言并没有那么大的差异。无论你用中文还是英文显示,对于具有相同含义的单词,它们的embedding都很接近。汉语中的 "跳 "与英语中的 "jump "接近,汉语中的 "鱼 "与英语中的 "fish "接近,汉语中的"游 "与英语中的 "swim "接近,也许在学习过程中它已经自动学会了。
可以用Mean Reciprocal Rank验证,缩写为MRR。MRR的值越高,不同embedding之间的Alignment就越好。更好的Alignment意味着,具有相同含义但来自不同语言的词将被转化为更接近的向量。
这条深蓝色的线是谷歌发布的104种语言的Multi-lingual BERT的MRR,它的值非常高,这说明不同语言之间没有太大的差别。Multi-lingual BERT只看意思,不同语言对它没有太大的差别。
数据量增加了五倍,才达到Alignment的效果。数据量是一个非常关键的因素,关系到能否成功地将不同的语言排列在一起。
如果BERT认为不同语言之间没有区别,那么在英文填空中为什么不用中文符号填空呢?说明它知道语言的信息也是不同的,并没有完全抹去语言信息
将所有中文的embbeding平均一下,英文的embbeding平均一下,发现两者之间存在着差距,这个差距用一个蓝色向量来表示。对一个Multi-lingual BERT输入英文问题和文章,他会输出一堆embedding,在embedding中加上这个蓝色的向量,这就是英语和汉语之间的差距。(此处是同义但不同语言,类比一下,所以同义的不同字代表的向量之间可能存在一个小小的偏差,改变偏差就能保证同义下改变字。)
参考:
李宏毅机器学习--self-supervised:BERT、GPT、Auto-encoder-CSDN博客