缓冲流
真正操作数据的还是基本流
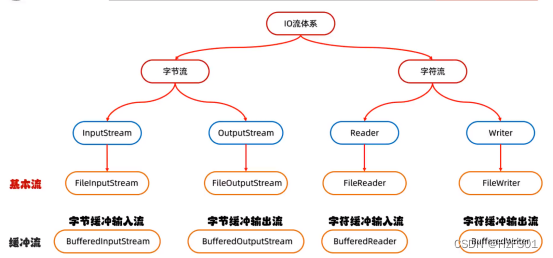
字节缓冲流
缓冲区是长度为8192的字节缓冲区 byte[] 8K
Bufferedininputstream

读取数据就是把数据放到缓冲区中,字节长度默认长度8192
关流只需要关缓冲流,因为在底层会关基本流
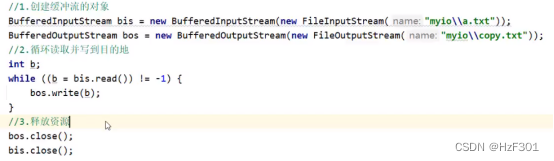
一次读多个字节

字节缓冲流提高效率的原理
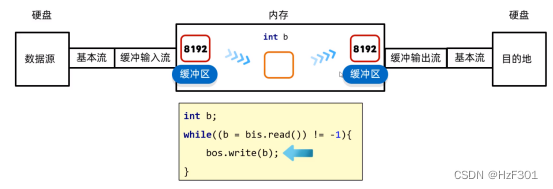
还是通过基本流读取文件数据,将数据放到缓冲输入流的缓冲区
通过read方法,将输入流的缓冲区中读取数据,写到输出流的缓冲区中
再通过基本流写到文件中
通俗讲:就是通过int b在两个缓冲区中倒手数据,在内存中,这个速度非常快,用时几乎忽略不计。Int b也可以是byte数组,更加快
字符缓冲流
缓冲区是长度为8192的字符缓冲区 char[] 一个char对应2个byte 所以是16K

Readline
读取一次读一行,遇到回车结束,但是不会读到回车符
循环读取文件中的数据
注意:循环条件是不等于null,而不是-1

字符缓冲输出流
续写的true是基本流的功能,bufferedwriter没有这功能



package exercise;
import java.io.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class exercise8 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new FileReader("day28\\src\\csb.txt"));
ArrayList<String> arr = new ArrayList<>();
String len;
while ((len = br.readLine()) != null) {
arr.add(len);
}
Collections.sort(arr, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return Integer.parseInt(o1.split("\\.")[0]) - Integer.parseInt(o2.split("\\.")[0]);
}
});
//还可以直接用treemap直接就排序了
BufferedWriter bw = new BufferedWriter(new FileWriter("day28\\src\\csb2.txt"));
for (String s : arr) {
bw.write(s);
bw.newLine();
}
bw.close();
br.close();
}
}
注意点:IO流最好不要在开头就把所有的都创建出来,这样就有可能在用bufferedwriter的时候,把文件清空了,导致read()读取不到数据

转换流
属于字符流
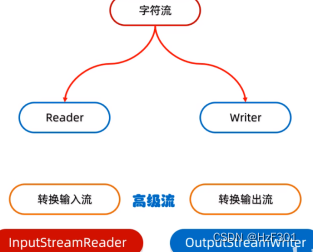

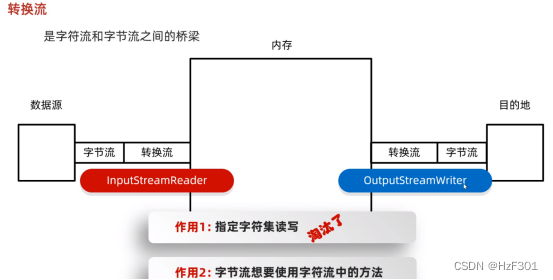
指定字符集读写被淘汰
JDK11时,filereader加入了一种新的构造方法
第二个参数直接写按照哪种字符集来读
Charset.forname()

同样,filewriter也是

GBK文件转成UTF-8

字节流读取中文,按行读,无乱码

序列化流/对象操作输出流
Objectoutputstream
写到文件中是乱码,不想让别人修改

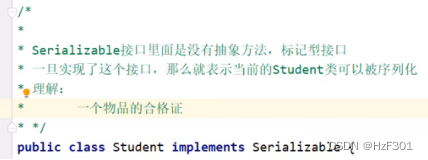
要让对象implements serializable
实现了这个接口,说明是可以被序列化的
serializable接口里没有抽象方法,所以不用重写

反序列化流/对象操作输入流
返回的是object类型,可以强转成原类型


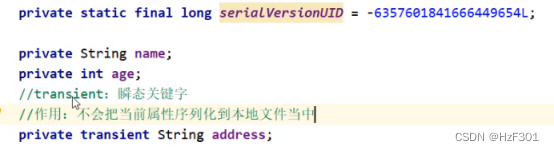
serialVersionUID是根据类里面所有的成员计算出来的
如果改变类里面的成员,uid就会变,相当于是一个版本号
如果给定了一个uid,则反序列的时候就不会报错;
没有给定uid,这时改变类里面的成员,代码就报错
如果不想某些属性被序列化到本地,则加上transient关键字
再反序列的时候,返回就是null了
注意点


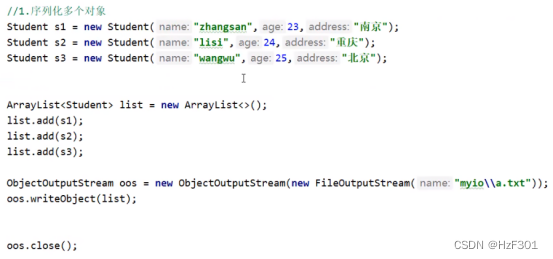
把对象装到集合中,读和写直接对list操作

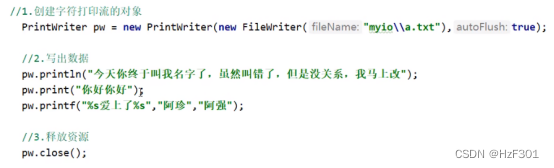
打印流
不能读,只能写
Printstream,printwriter

字节打印流
没有缓冲区



字符打印流
有缓冲区,可以手动开自动刷新,一般都是开



System.out.println()
Out是printstream类,system.out相对于就是获取了一个字节打印流对象
这个打印流默认指向控制台


解压缩流/压缩流

Zipinputstream
getNextEntry:获取到文件夹中所有的文件,包括子文件夹中的文件,返回一个entry对象
Entry.isDirectory()判断是不是文件夹。注意:没有isfile方法
Entry.toString()地址变字符串形式


压缩
![]()
![]()
Zipentry():括号里面表示压缩包里面内部的路径
如果是D:\\ ,则压缩包里会出现一个D盘,然后才是跟着的aaa文件夹


Commons-io


copyDirectory:是将文件夹里面的内容copy到目的地文件夹里面
copyDirectoryToDirectory:是将文件夹copy到目的地新建的文件夹里面
Clean:清空文件夹里面的所有文件和文件夹,只保留最外层的文件夹

Hutool

Touch:可以根据传入的file对象,创建文件,而且如果父级路径不存在,他也可以一同创建。之前的createnewfile就不行,如果父级路径不存在,就创建不了
制造假数据
网络爬取
写法一
package exercise;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Random;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class exercise1 {
public static void main(String[] args) throws IOException {
/*
制造假数据:
获取姓氏:https://hanyu.baidu.com/shici/detail?pid=0b2f26d4c0ddb3ee693fdb1137ee1b0d&from=kg0
获取男生名字:http://www.haoming8.cn/baobao/10881.html
获取女生名字:http://www.haoming8.cn/baobao/7641.html
*/
//1.定义变量记录网址
String familyNameNet = "https://mp.weixin.qq.com/s?__biz=MzU4MDcwMjkxNw==&mid=2247492706&idx=4&sn=021c357e8f9ac5e13040ae8256b4cb68&chksm=fd5063c8ca27eadeb97c9682dbecdd8ebc3784f5abdd2e09819a1612e439003079c646909ca2&scene=27";
String boyNameNet = "http://www.haoming8.cn/baobao/10881.html";
String girlNameNet = "http://www.haoming8.cn/baobao/7641.html";
//2.爬取数据,把网址上所有的数据拼接成一个字符串
String familyNameStr = webCrawler(familyNameNet);
String boyNameStr = webCrawler(boyNameNet);
String girlNameStr = webCrawler(girlNameNet);
//3.通过正则表达式,把其中符合要求的数据获取出来
ArrayList<String> familyNameTempList = getData(familyNameStr, "([\\u4E00-\\u9FA5] ){3}([\\u4E00-\\u9FA5])", 0);
ArrayList<String> boyNameTempList = getData(boyNameStr, "([\\u4E00-\\u9FA5]{2})(、|。)", 1);
ArrayList<String> girlNameTempList = getData(girlNameStr, "(([\\u4E00-\\u9FA5]{2} ){4}[\\u4E00-\\u9FA5]{2})", 0);
//4.处理数据
ArrayList<String> familyNameList = new ArrayList<>();
for (String s : familyNameTempList) {
String[] split = s.split(" ");
familyNameList.addAll(List.of(split));
}
ArrayList<String> boyNameList = new ArrayList<>();
for (String s : boyNameTempList) {
if (!boyNameList.contains(s)) {
boyNameList.add(s);
}
}
ArrayList<String> girlNameList = new ArrayList<>();
for (String s : girlNameTempList) {
String[] split = s.split(" ");
girlNameList.addAll(List.of(split));
}
//5.生成假数据
ArrayList<String> list = getInfo(familyNameList, boyNameList, girlNameList, 50, 50);
System.out.println(list);
//6.写入文件
BufferedWriter bw = new BufferedWriter(new FileWriter("day30\\src\\names.txt"));
for (String s : list) {
bw.write(s);
bw.newLine();
}
bw.close();
}
private static ArrayList<String> getInfo(ArrayList<String> familyNameList, ArrayList<String> boyNameList, ArrayList<String> girlNameList, int boyCount, int girlCount) {
ArrayList<String> list = new ArrayList<>();
Collections.shuffle(familyNameList);
Collections.shuffle(boyNameList);
Collections.shuffle(girlNameList);
Random r = new Random();
//获取男生
for (int i = 0; i < boyCount; i++) {
int age = r.nextInt(8) + 18;
list.add(familyNameList.get(i) + boyNameList.get(i) + "-男-" + age);
}
//获取女生
for (int i = 0; i < girlCount; i++) {
int age = r.nextInt(8) + 18;
list.add(familyNameList.get(i) + girlNameList.get(i) + "-女-" + age);
}
Collections.shuffle(list);
return list;
}
private static ArrayList<String> getData(String str, String regex, int index) {
ArrayList<String> arr = new ArrayList<>();
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(str);
while (m.find()) {
arr.add(m.group(index));
}
return arr;
}
private static String webCrawler(String net) throws IOException {
StringBuilder sb = new StringBuilder();
URL url = new URL(net);
URLConnection conn = url.openConnection();
InputStreamReader isr = new InputStreamReader(conn.getInputStream());
int b;
while ((b = isr.read()) != -1) {
sb.append((char) b);
}
isr.close();
return sb.toString();
}
}写法二:用hutool写
package exercise;
import cn.hutool.core.io.FileUtil;
import cn.hutool.core.util.ReUtil;
import cn.hutool.http.HttpUtil;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Random;
public class exercise2 {
public static void main(String[] args) throws IOException {
/*
制造假数据:
获取姓氏:https://hanyu.baidu.com/shici/detail?pid=0b2f26d4c0ddb3ee693fdb1137ee1b0d&from=kg0
获取男生名字:http://www.haoming8.cn/baobao/10881.html
获取女生名字:http://www.haoming8.cn/baobao/7641.html
*/
//1.定义变量记录网址
String familyNameNet = "https://mp.weixin.qq.com/s?__biz=MzU4MDcwMjkxNw==&mid=2247492706&idx=4&sn=021c357e8f9ac5e13040ae8256b4cb68&chksm=fd5063c8ca27eadeb97c9682dbecdd8ebc3784f5abdd2e09819a1612e439003079c646909ca2&scene=27";
String boyNameNet = "http://www.haoming8.cn/baobao/10881.html";
String girlNameNet = "http://www.haoming8.cn/baobao/7641.html";
//2.爬取数据,把网址上所有的数据拼接成一个字符串
String familyNameStr = HttpUtil.get(familyNameNet);
String boyNameStr = HttpUtil.get(boyNameNet);
String girlNameStr = HttpUtil.get(girlNameNet);
//3.通过正则表达式,把其中符合要求的数据获取出来
List<String> familyNameTempList = ReUtil.findAll("([\\u4E00-\\u9FA5] ){3}([\\u4E00-\\u9FA5])", familyNameStr, 0);
List<String> boyNameTempList = ReUtil.findAll("([\\u4E00-\\u9FA5]{2})(、|。)", boyNameStr, 1);
List<String> girlNameTempList = ReUtil.findAll("(([\\u4E00-\\u9FA5]{2} ){4}[\\u4E00-\\u9FA5]{2})", girlNameStr, 0);
//4.处理数据
ArrayList<String> familyNameList = new ArrayList<>();
for (String s : familyNameTempList) {
String[] split = s.split(" ");
familyNameList.addAll(List.of(split));
}
ArrayList<String> boyNameList = new ArrayList<>();
for (String s : boyNameTempList) {
if (!boyNameList.contains(s)) {
boyNameList.add(s);
}
}
ArrayList<String> girlNameList = new ArrayList<>();
for (String s : girlNameTempList) {
String[] split = s.split(" ");
girlNameList.addAll(List.of(split));
}
//5.生成假数据
ArrayList<String> list = getInfo(familyNameList, boyNameList, girlNameList, 50, 50);
System.out.println(list);
//6.写入文件 写到了out文件夹中的production里
FileUtil.writeLines(list, "day30\\src\\names.txt", "UTF-8");
}
private static ArrayList<String> getInfo(ArrayList<String> familyNameList, ArrayList<String> boyNameList, ArrayList<String> girlNameList, int boyCount, int girlCount) {
ArrayList<String> list = new ArrayList<>();
Collections.shuffle(familyNameList);
Collections.shuffle(boyNameList);
Collections.shuffle(girlNameList);
Random r = new Random();
//获取男生
for (int i = 0; i < boyCount; i++) {
int age = r.nextInt(8) + 18;
list.add(familyNameList.get(i) + boyNameList.get(i) + "-男-" + age);
}
//获取女生
for (int i = 0; i < girlCount; i++) {
int age = r.nextInt(8) + 18;
list.add(familyNameList.get(i) + girlNameList.get(i) + "-女-" + age);
}
Collections.shuffle(list);
return list;
}
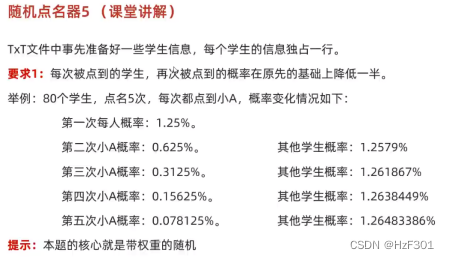
}随机点名器
package exercise;
import java.io.*;
import java.util.ArrayList;
import java.util.Arrays;
public class exercise7 {
public static void main(String[] args) throws IOException {
//获取数据
File f = new File("day30\\src\\names2.txt");
BufferedReader br1 = new BufferedReader(new FileReader(f));
ArrayList<Student> list = new ArrayList<>();
String s;
while ((s = br1.readLine()) != null) {
String[] split = s.split("-");
list.add(new Student(split[0], split[1], Integer.parseInt(split[2]), Double.parseDouble(split[3])));
}
br1.close();
//得到总权重
double sum = 0;
for (Student stu : list) {
sum += stu.getWeight();
}
//得到每一个的权重
double[] arr = new double[list.size()];
int index = 0;
for (Student stu : list) {
arr[index] = stu.getWeight() / sum;
index++;
}
//计算每个人落下的权重范围
for (int i = 1; i < arr.length; i++) {
arr[i] += arr[i - 1];
}
System.out.println(Arrays.toString(arr));
//得到随机数
double number = Math.random();
int i = -Arrays.binarySearch(arr, number) - 1;
//得到抽中的姓名
Student stu = list.get(i);
//改变权重
stu.setWeight(stu.getWeight() / 2);
//写入文件
BufferedWriter bw = new BufferedWriter(new FileWriter(f));
for (Student student : list) {
bw.write(student.toString());
bw.newLine();
}
bw.close();
}
}